Cheat Sheet¶
This page shows some code snippets of how to use Tianshou to develop new algorithms / apply algorithms to new scenarios.
By the way, some of these issues can be resolved by using a gym.Wrapper. It could be a universal solution in the policy-environment interaction. But you can also use the batch processor Handle Batched Data Stream in Collector.
Build Policy Network¶
See Build the Network.
Build New Policy¶
See BasePolicy.
Customize Training Process¶
Parallel Sampling¶
Tianshou provides the following classes for parallel environment simulation:
DummyVectorEnvis for pseudo-parallel simulation (implemented with a for-loop, useful for debugging).SubprocVectorEnvuses multiple processes for parallel simulation. This is the most often choice for parallel simulation.ShmemVectorEnvhas a similar implementation toSubprocVectorEnv, but is optimized (in terms of both memory footprint and simulation speed) for environments with large observations such as images.RayVectorEnvis currently the only choice for parallel simulation in a cluster with multiple machines.
Although these classes are optimized for different scenarios, they have exactly the same APIs because they are sub-classes of BaseVectorEnv. Just provide a list of functions who return environments upon called, and it is all set.
env_fns = [lambda x=i: MyTestEnv(size=x) for i in [2, 3, 4, 5]]
venv = SubprocVectorEnv(env_fns) # DummyVectorEnv, ShmemVectorEnv, or RayVectorEnv, whichever you like.
venv.reset() # returns the initial observations of each environment
venv.step(actions) # provide actions for each environment and get their results
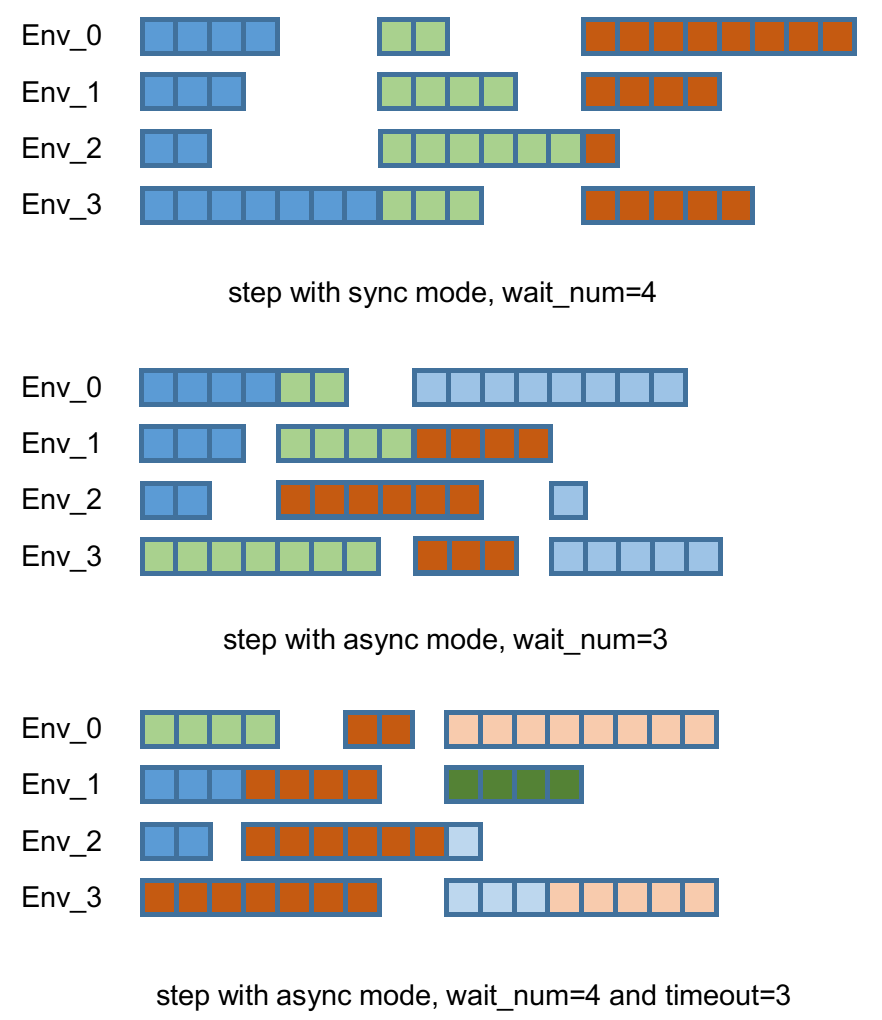
By default, parallel environment simulation is synchronous: a step is done after all environments have finished a step. Synchronous simulation works well if each step of environments costs roughly the same time.
In case the time cost of environments varies a lot (e.g. 90% step cost 1s, but 10% cost 10s) where slow environments lag fast environments behind, async simulation can be used (related to Issue 103). The idea is to start those finished environments without waiting for slow environments.
Asynchronous simulation is a built-in functionality of BaseVectorEnv. Just provide wait_num or timeout (or both) and async simulation works.
env_fns = [lambda x=i: MyTestEnv(size=x, sleep=x) for i in [2, 3, 4, 5]]
# DummyVectorEnv, ShmemVectorEnv, or RayVectorEnv, whichever you like.
venv = SubprocVectorEnv(env_fns, wait_num=3, timeout=0.2)
venv.reset() # returns the initial observations of each environment
# returns "wait_num" steps or finished steps after "timeout" seconds,
# whichever occurs first.
venv.step(actions, ready_id)
If we have 4 envs and set wait_num = 3, each of the step only returns 3 results of these 4 envs.
You can treat the timeout parameter as a dynamic wait_num. In each vectorized step it only returns the environments finished within the given time. If there is no such environment, it will wait until any of them finished.
The figure in the right gives an intuitive comparison among synchronous/asynchronous simulation.
Warning
If you use your own environment, please make sure the seed method is set up properly, e.g.,
def seed(self, seed):
np.random.seed(seed)
Otherwise, the outputs of these envs may be the same with each other.
Handle Batched Data Stream in Collector¶
This is related to Issue 42.
If you want to get log stat from data stream / pre-process batch-image / modify the reward with given env info, use preproces_fn in Collector. This is a hook which will be called before the data adding into the buffer.
This function receives up to 7 keys obs, act, rew, done, obs_next, info, and policy, as listed in Batch. It returns the modified part within a Batch. Only obs is defined at env.reset, while every key is specified for normal steps.
These variables are intended to gather all the information requires to keep track of a simulation step, namely the (observation, action, reward, done flag, next observation, info, intermediate result of the policy) at time t, for the whole duration of the simulation.
For example, you can write your hook as:
import numpy as np
from collections import deque
class MyProcessor:
def __init__(self, size=100):
self.episode_log = None
self.main_log = deque(maxlen=size)
self.main_log.append(0)
self.baseline = 0
def preprocess_fn(**kwargs):
"""change reward to zero mean"""
# if only obs exist -> reset
# if obs/act/rew/done/... exist -> normal step
if 'rew' not in kwargs:
# means that it is called after env.reset(), it can only process the obs
return Batch() # none of the variables are needed to be updated
else:
n = len(kwargs['rew']) # the number of envs in collector
if self.episode_log is None:
self.episode_log = [[] for i in range(n)]
for i in range(n):
self.episode_log[i].append(kwargs['rew'][i])
kwargs['rew'][i] -= self.baseline
for i in range(n):
if kwargs['done']:
self.main_log.append(np.mean(self.episode_log[i]))
self.episode_log[i] = []
self.baseline = np.mean(self.main_log)
return Batch(rew=kwargs['rew'])
And finally,
test_processor = MyProcessor(size=100)
collector = Collector(policy, env, buffer, test_processor.preprocess_fn)
Some examples are in test/base/test_collector.py.
RNN-style Training¶
This is related to Issue 19.
First, add an argument “stack_num” to ReplayBuffer:
buf = ReplayBuffer(size=size, stack_num=stack_num)
Then, change the network to recurrent-style, for example, Recurrent, RecurrentActorProb and RecurrentCritic.
The above code supports only stacked-observation. If you want to use stacked-action (for Q(stacked-s, stacked-a)), stacked-reward, or other stacked variables, you can add a gym.Wrapper to modify the state representation. For example, if we add a wrapper that map [s, a] pair to a new state:
Before: (s, a, s’, r, d) stored in replay buffer, and get stacked s;
After applying wrapper: ([s, a], a, [s’, a’], r, d) stored in replay buffer, and get both stacked s and a.
User-defined Environment and Different State Representation¶
This is related to Issue 38 and Issue 69.
First of all, your self-defined environment must follow the Gym’s API, some of them are listed below:
reset() -> state
step(action) -> state, reward, done, info
seed(s) -> List[int]
render(mode) -> Any
close() -> None
observation_space: gym.Space
action_space: gym.Space
The state can be a numpy.ndarray or a Python dictionary. Take “FetchReach-v1” as an example:
>>> e = gym.make('FetchReach-v1')
>>> e.reset()
{'observation': array([ 1.34183265e+00, 7.49100387e-01, 5.34722720e-01, 1.97805133e-04,
7.15193042e-05, 7.73933014e-06, 5.51992816e-08, -2.42927453e-06,
4.73325650e-06, -2.28455228e-06]),
'achieved_goal': array([1.34183265, 0.74910039, 0.53472272]),
'desired_goal': array([1.24073906, 0.77753463, 0.63457791])}
It shows that the state is a dictionary which has 3 keys. It will stored in ReplayBuffer as:
>>> from tianshou.data import ReplayBuffer
>>> b = ReplayBuffer(size=3)
>>> b.add(obs=e.reset(), act=0, rew=0, done=0)
>>> print(b)
ReplayBuffer(
act: array([0, 0, 0]),
done: array([0, 0, 0]),
info: Batch(),
obs: Batch(
achieved_goal: array([[1.34183265, 0.74910039, 0.53472272],
[0. , 0. , 0. ],
[0. , 0. , 0. ]]),
desired_goal: array([[1.42154265, 0.62505137, 0.62929863],
[0. , 0. , 0. ],
[0. , 0. , 0. ]]),
observation: array([[ 1.34183265e+00, 7.49100387e-01, 5.34722720e-01,
1.97805133e-04, 7.15193042e-05, 7.73933014e-06,
5.51992816e-08, -2.42927453e-06, 4.73325650e-06,
-2.28455228e-06],
[ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00],
[ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00]]),
),
policy: Batch(),
rew: array([0, 0, 0]),
)
>>> print(b.obs.achieved_goal)
[[1.34183265 0.74910039 0.53472272]
[0. 0. 0. ]
[0. 0. 0. ]]
And the data batch sampled from this replay buffer:
>>> batch, indice = b.sample(2)
>>> batch.keys()
['act', 'done', 'info', 'obs', 'obs_next', 'policy', 'rew']
>>> batch.obs[-1]
Batch(
achieved_goal: array([1.34183265, 0.74910039, 0.53472272]),
desired_goal: array([1.42154265, 0.62505137, 0.62929863]),
observation: array([ 1.34183265e+00, 7.49100387e-01, 5.34722720e-01, 1.97805133e-04,
7.15193042e-05, 7.73933014e-06, 5.51992816e-08, -2.42927453e-06,
4.73325650e-06, -2.28455228e-06]),
)
>>> batch.obs.desired_goal[-1] # recommended
array([1.42154265, 0.62505137, 0.62929863])
>>> batch.obs[-1].desired_goal # not recommended
array([1.42154265, 0.62505137, 0.62929863])
>>> batch[-1].obs.desired_goal # not recommended
array([1.42154265, 0.62505137, 0.62929863])
Thus, in your self-defined network, just change the forward function as:
def forward(self, s, ...):
# s is a batch
observation = s.observation
achieved_goal = s.achieved_goal
desired_goal = s.desired_goal
...
For self-defined class, the replay buffer will store the reference into a numpy.ndarray, e.g.:
>>> import networkx as nx
>>> b = ReplayBuffer(size=3)
>>> b.add(obs=nx.Graph(), act=0, rew=0, done=0)
>>> print(b)
ReplayBuffer(
act: array([0, 0, 0]),
done: array([0, 0, 0]),
info: Batch(),
obs: array([<networkx.classes.graph.Graph object at 0x7f5c607826a0>, None,
None], dtype=object),
policy: Batch(),
rew: array([0, 0, 0]),
)
But the state stored in the buffer may be a shallow-copy. To make sure each of your state stored in the buffer is distinct, please return the deep-copy version of your state in your env:
def reset():
return copy.deepcopy(self.graph)
def step(a):
...
return copy.deepcopy(self.graph), reward, done, {}
Multi-Agent Reinforcement Learning¶
This is related to Issue 121. The discussion is still goes on.
With the flexible core APIs, Tianshou can support multi-agent reinforcement learning with minimal efforts.
Currently, we support three types of multi-agent reinforcement learning paradigms:
Simultaneous move: at each timestep, all the agents take their actions (example: moba games)
Cyclic move: players take action in turn (example: Go game)
Conditional move, at each timestep, the environment conditionally selects an agent to take action. (example: Pig Game)
We mainly address these multi-agent RL problems by converting them into traditional RL formulations.
For simultaneous move, the solution is simple: we can just add a num_agent dimension to state, action, and reward. Nothing else is going to change.
For 2 & 3 (cyclic move and conditional move), they can be unified into a single framework: at each timestep, the environment selects an agent with id agent_id to play. Since multi-agents are usually wrapped into one object (which we call “abstract agent”), we can pass the agent_id to the “abstract agent”, leaving it to further call the specific agent.
In addition, legal actions in multi-agent RL often vary with timestep (just like Go games), so the environment should also passes the legal action mask to the “abstract agent”, where the mask is a boolean array that “True” for available actions and “False” for illegal actions at the current step. Below is a figure that explains the abstract agent.
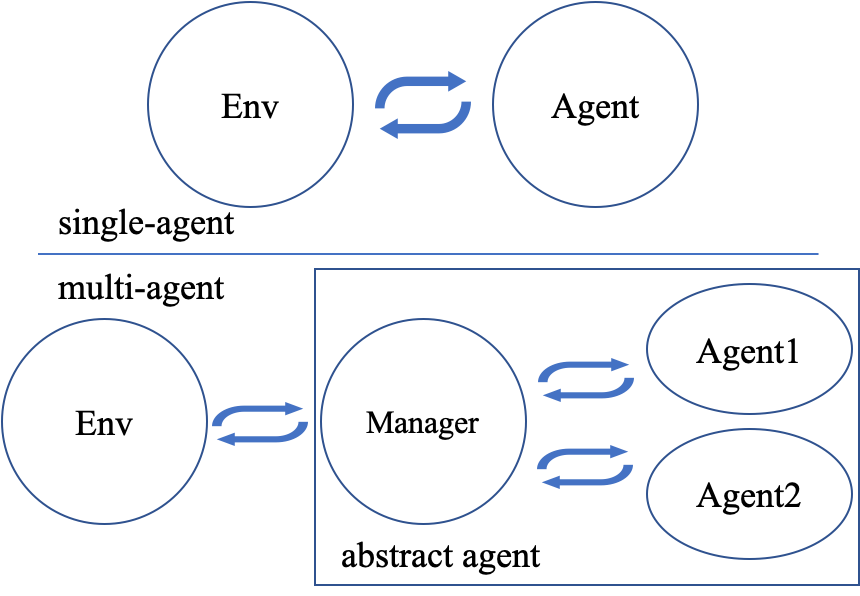
The above description gives rise to the following formulation of multi-agent RL:
action = policy(state, agent_id, mask)
(next_state, next_agent_id, next_mask), reward = env.step(action)
By constructing a new state state_ = (state, agent_id, mask), essentially we can return to the typical formulation of RL:
action = policy(state_)
next_state_, reward = env.step(action)
Following this idea, we write a tiny example of playing Tic Tac Toe against a random player by using a Q-lerning algorithm. The tutorial is at Multi-Agent RL.