tianshou.policy¶
-
class
tianshou.policy.A2CPolicy(actor: torch.nn.modules.module.Module, critic: torch.nn.modules.module.Module, optim: torch.optim.optimizer.Optimizer, dist_fn: torch.distributions.distribution.Distribution = <class 'torch.distributions.categorical.Categorical'>, discount_factor: float = 0.99, vf_coef: float = 0.5, ent_coef: float = 0.01, max_grad_norm: Optional[float] = None, gae_lambda: float = 0.95, reward_normalization: bool = False, **kwargs)[source]¶ Bases:
tianshou.policy.modelfree.pg.PGPolicyImplementation of Synchronous Advantage Actor-Critic. arXiv:1602.01783
- Parameters
actor (torch.nn.Module) – the actor network following the rules in
BasePolicy. (s -> logits)critic (torch.nn.Module) – the critic network. (s -> V(s))
optim (torch.optim.Optimizer) – the optimizer for actor and critic network.
dist_fn (torch.distributions.Distribution) – for computing the action, defaults to
torch.distributions.Categorical.discount_factor (float) – in [0, 1], defaults to 0.99.
vf_coef (float) – weight for value loss, defaults to 0.5.
ent_coef (float) – weight for entropy loss, defaults to 0.01.
max_grad_norm (float) – clipping gradients in back propagation, defaults to
None.gae_lambda (float) – in [0, 1], param for Generalized Advantage Estimation, defaults to 0.95.
See also
Please refer to
BasePolicyfor more detailed explanation.-
forward(batch: tianshou.data.batch.Batch, state: Optional[Union[dict, tianshou.data.batch.Batch, numpy.ndarray]] = None, **kwargs) → tianshou.data.batch.Batch[source]¶ Compute action over the given batch data.
- Returns
A
Batchwhich has 4 keys:actthe action.logitsthe network’s raw output.distthe action distribution.statethe hidden state.
See also
Please refer to
forward()for more detailed explanation.
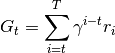
 is the terminal time step,
is the terminal time step, -
class
tianshou.policy.BasePolicy(**kwargs)[source]¶ Bases:
abc.ABC,torch.nn.modules.module.ModuleTianshou aims to modularizing RL algorithms. It comes into several classes of policies in Tianshou. All of the policy classes must inherit
BasePolicy.A policy class typically has four parts:
__init__(): initialize the policy, including coping the target network and so on;forward(): compute action with given observation;process_fn(): pre-process data from the replay buffer (this function can interact with replay buffer);learn(): update policy with a given batch of data.
Most of the policy needs a neural network to predict the action and an optimizer to optimize the policy. The rules of self-defined networks are:
Input: observation
obs(may be anumpy.ndarray, atorch.Tensor, a dict or any others), hidden statestate(for RNN usage), and other informationinfoprovided by the environment.Output: some
logits, the next hidden statestate, and the intermediate result during policy forwarding procedurepolicy. Thelogitscould be a tuple instead of atorch.Tensor. It depends on how the policy process the network output. For example, in PPO, the return of the network might be(mu, sigma), statefor Gaussian policy. Thepolicycan be a Batch of torch.Tensor or other things, which will be stored in the replay buffer, and can be accessed in the policy update process (e.g. inpolicy.learn(), thebatch.policyis what you need).
Since
BasePolicyinheritstorch.nn.Module, you can useBasePolicyalmost the same astorch.nn.Module, for instance, loading and saving the model:torch.save(policy.state_dict(), 'policy.pth') policy.load_state_dict(torch.load('policy.pth'))
-
static
compute_episodic_return(batch: tianshou.data.batch.Batch, v_s_: Optional[Union[numpy.ndarray, torch.Tensor]] = None, gamma: float = 0.99, gae_lambda: float = 0.95) → tianshou.data.batch.Batch[source]¶ Compute returns over given full-length episodes, including the implementation of Generalized Advantage Estimator (arXiv:1506.02438).
- Parameters
batch (
Batch) – a data batch which contains several full-episode data chronologically.v_s (numpy.ndarray) – the value function of all next states
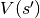 .
.gamma (float) – the discount factor, should be in [0, 1], defaults to 0.99.
gae_lambda (float) – the parameter for Generalized Advantage Estimation, should be in [0, 1], defaults to 0.95.
- Returns
a Batch. The result will be stored in batch.returns.
-
static
compute_nstep_return(batch: tianshou.data.batch.Batch, buffer: tianshou.data.buffer.ReplayBuffer, indice: numpy.ndarray, target_q_fn: Callable[[tianshou.data.buffer.ReplayBuffer, numpy.ndarray], torch.Tensor], gamma: float = 0.99, n_step: int = 1, rew_norm: bool = False) → numpy.ndarray[source]¶ Compute n-step return for Q-learning targets:
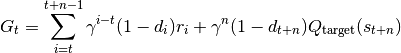
, where
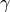 is the discount factor,
is the discount factor,
![\gamma \in [0, 1]](../_images/math/82a40a7074383d0baff2f0e00b6a0e46f7aa1548.png) ,
, 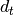 is the done flag of step
is the done flag of step
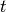 .
.- Parameters
batch (
Batch) – a data batch, which is equal to buffer[indice].buffer (
ReplayBuffer) – a data buffer which contains several full-episode data chronologically.indice (numpy.ndarray) – sampled timestep.
target_q_fn (function) – a function receives
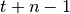 step’s
data and compute target Q value.
step’s
data and compute target Q value.gamma (float) – the discount factor, should be in [0, 1], defaults to 0.99.
n_step (int) – the number of estimation step, should be an int greater than 0, defaults to 1.
rew_norm (bool) – normalize the reward to Normal(0, 1), defaults to
False.
- Returns
a Batch. The result will be stored in batch.returns as a torch.Tensor with shape (bsz, ).
-
abstract
forward(batch: tianshou.data.batch.Batch, state: Optional[Union[dict, tianshou.data.batch.Batch, numpy.ndarray]] = None, **kwargs) → tianshou.data.batch.Batch[source]¶ Compute action over the given batch data.
- Returns
A
Batchwhich MUST have the following keys:actan numpy.ndarray or a torch.Tensor, the action over given batch data.statea dict, an numpy.ndarray or a torch.Tensor, the internal state of the policy,Noneas default.
Other keys are user-defined. It depends on the algorithm. For example,
# some code return Batch(logits=..., act=..., state=None, dist=...)
After version >= 0.2.3, the keyword “policy” is reserverd and the corresponding data will be stored into the replay buffer in numpy. For instance,
# some code return Batch(..., policy=Batch(log_prob=dist.log_prob(act))) # and in the sampled data batch, you can directly call # batch.policy.log_prob to get your data, although it is stored in # np.ndarray.
-
class
tianshou.policy.DDPGPolicy(actor: torch.nn.modules.module.Module, actor_optim: torch.optim.optimizer.Optimizer, critic: torch.nn.modules.module.Module, critic_optim: torch.optim.optimizer.Optimizer, tau: float = 0.005, gamma: float = 0.99, exploration_noise: Optional[tianshou.exploration.random.BaseNoise] = <tianshou.exploration.random.GaussianNoise object>, action_range: Optional[Tuple[float, float]] = None, reward_normalization: bool = False, ignore_done: bool = False, estimation_step: int = 1, **kwargs)[source]¶ Bases:
tianshou.policy.base.BasePolicyImplementation of Deep Deterministic Policy Gradient. arXiv:1509.02971
- Parameters
actor (torch.nn.Module) – the actor network following the rules in
BasePolicy. (s -> logits)actor_optim (torch.optim.Optimizer) – the optimizer for actor network.
critic (torch.nn.Module) – the critic network. (s, a -> Q(s, a))
critic_optim (torch.optim.Optimizer) – the optimizer for critic network.
tau (float) – param for soft update of the target network, defaults to 0.005.
gamma (float) – discount factor, in [0, 1], defaults to 0.99.
exploration_noise (BaseNoise) – the exploration noise, add to the action, defaults to
GaussianNoise(sigma=0.1).action_range ((float, float)) – the action range (minimum, maximum).
reward_normalization (bool) – normalize the reward to Normal(0, 1), defaults to
False.ignore_done (bool) – ignore the done flag while training the policy, defaults to
False.estimation_step (int) – greater than 1, the number of steps to look ahead.
See also
Please refer to
BasePolicyfor more detailed explanation.-
forward(batch: tianshou.data.batch.Batch, state: Optional[Union[dict, tianshou.data.batch.Batch, numpy.ndarray]] = None, model: str = 'actor', input: str = 'obs', explorating: bool = True, **kwargs) → tianshou.data.batch.Batch[source]¶ Compute action over the given batch data.
- Returns
A
Batchwhich has 2 keys:actthe action.statethe hidden state.
See also
Please refer to
forward()for more detailed explanation.
-
learn(batch: tianshou.data.batch.Batch, **kwargs) → Dict[str, float][source]¶ Update policy with a given batch of data.
- Returns
A dict which includes loss and its corresponding label.
-
process_fn(batch: tianshou.data.batch.Batch, buffer: tianshou.data.buffer.ReplayBuffer, indice: numpy.ndarray) → tianshou.data.batch.Batch[source]¶ Pre-process the data from the provided replay buffer. Check out Policy for more information.
-
class
tianshou.policy.DQNPolicy(model: torch.nn.modules.module.Module, optim: torch.optim.optimizer.Optimizer, discount_factor: float = 0.99, estimation_step: int = 1, target_update_freq: Optional[int] = 0, **kwargs)[source]¶ Bases:
tianshou.policy.base.BasePolicyImplementation of Deep Q Network. arXiv:1312.5602 Implementation of Double Q-Learning. arXiv:1509.06461
- Parameters
model (torch.nn.Module) – a model following the rules in
BasePolicy. (s -> logits)optim (torch.optim.Optimizer) – a torch.optim for optimizing the model.
discount_factor (float) – in [0, 1].
estimation_step (int) – greater than 1, the number of steps to look ahead.
target_update_freq (int) – the target network update frequency (
0if you do not use the target network).
See also
Please refer to
BasePolicyfor more detailed explanation.-
forward(batch: tianshou.data.batch.Batch, state: Optional[Union[dict, tianshou.data.batch.Batch, numpy.ndarray]] = None, model: str = 'model', input: str = 'obs', eps: Optional[float] = None, **kwargs) → tianshou.data.batch.Batch[source]¶ Compute action over the given batch data.
- Parameters
eps (float) – in [0, 1], for epsilon-greedy exploration method.
- Returns
A
Batchwhich has 3 keys:actthe action.logitsthe network’s raw output.statethe hidden state.
See also
Please refer to
forward()for more detailed explanation.
-
learn(batch: tianshou.data.batch.Batch, **kwargs) → Dict[str, float][source]¶ Update policy with a given batch of data.
- Returns
A dict which includes loss and its corresponding label.
-
process_fn(batch: tianshou.data.batch.Batch, buffer: tianshou.data.buffer.ReplayBuffer, indice: numpy.ndarray) → tianshou.data.batch.Batch[source]¶ Compute the n-step return for Q-learning targets:
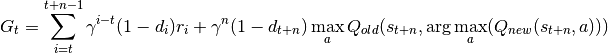
, where
is the discount factor,
, is the done flag of step
. If there is no target network, the 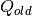 is equal
to
is equal
to 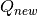 .
.
-
class
tianshou.policy.ImitationPolicy(model: torch.nn.modules.module.Module, optim: torch.optim.optimizer.Optimizer, mode: str = 'continuous', **kwargs)[source]¶ Bases:
tianshou.policy.base.BasePolicyImplementation of vanilla imitation learning (for continuous action space).
- Parameters
model (torch.nn.Module) – a model following the rules in
BasePolicy. (s -> a)optim (torch.optim.Optimizer) – for optimizing the model.
mode (str) – indicate the imitation type (“continuous” or “discrete” action space), defaults to “continuous”.
See also
Please refer to
BasePolicyfor more detailed explanation.-
forward(batch: tianshou.data.batch.Batch, state: Optional[Union[dict, tianshou.data.batch.Batch, numpy.ndarray]] = None, **kwargs) → tianshou.data.batch.Batch[source]¶ Compute action over the given batch data.
- Returns
A
Batchwhich MUST have the following keys:actan numpy.ndarray or a torch.Tensor, the action over given batch data.statea dict, an numpy.ndarray or a torch.Tensor, the internal state of the policy,Noneas default.
Other keys are user-defined. It depends on the algorithm. For example,
# some code return Batch(logits=..., act=..., state=None, dist=...)
After version >= 0.2.3, the keyword “policy” is reserverd and the corresponding data will be stored into the replay buffer in numpy. For instance,
# some code return Batch(..., policy=Batch(log_prob=dist.log_prob(act))) # and in the sampled data batch, you can directly call # batch.policy.log_prob to get your data, although it is stored in # np.ndarray.
-
class
tianshou.policy.PGPolicy(model: torch.nn.modules.module.Module, optim: torch.optim.optimizer.Optimizer, dist_fn: torch.distributions.distribution.Distribution = <class 'torch.distributions.categorical.Categorical'>, discount_factor: float = 0.99, reward_normalization: bool = False, **kwargs)[source]¶ Bases:
tianshou.policy.base.BasePolicyImplementation of Vanilla Policy Gradient.
- Parameters
model (torch.nn.Module) – a model following the rules in
BasePolicy. (s -> logits)optim (torch.optim.Optimizer) – a torch.optim for optimizing the model.
dist_fn (torch.distributions.Distribution) – for computing the action.
discount_factor (float) – in [0, 1].
See also
Please refer to
BasePolicyfor more detailed explanation.-
forward(batch: tianshou.data.batch.Batch, state: Optional[Union[dict, tianshou.data.batch.Batch, numpy.ndarray]] = None, **kwargs) → tianshou.data.batch.Batch[source]¶ Compute action over the given batch data.
- Returns
A
Batchwhich has 4 keys:actthe action.logitsthe network’s raw output.distthe action distribution.statethe hidden state.
See also
Please refer to
forward()for more detailed explanation.
-
class
tianshou.policy.PPOPolicy(actor: torch.nn.modules.module.Module, critic: torch.nn.modules.module.Module, optim: torch.optim.optimizer.Optimizer, dist_fn: torch.distributions.distribution.Distribution, discount_factor: float = 0.99, max_grad_norm: Optional[float] = None, eps_clip: float = 0.2, vf_coef: float = 0.5, ent_coef: float = 0.01, action_range: Optional[Tuple[float, float]] = None, gae_lambda: float = 0.95, dual_clip: Optional[float] = None, value_clip: bool = True, reward_normalization: bool = True, **kwargs)[source]¶ Bases:
tianshou.policy.modelfree.pg.PGPolicyImplementation of Proximal Policy Optimization. arXiv:1707.06347
- Parameters
actor (torch.nn.Module) – the actor network following the rules in
BasePolicy. (s -> logits)critic (torch.nn.Module) – the critic network. (s -> V(s))
optim (torch.optim.Optimizer) – the optimizer for actor and critic network.
dist_fn (torch.distributions.Distribution) – for computing the action.
discount_factor (float) – in [0, 1], defaults to 0.99.
max_grad_norm (float) – clipping gradients in back propagation, defaults to
None.eps_clip (float) –
 in
in 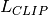 in the original
paper, defaults to 0.2.
in the original
paper, defaults to 0.2.vf_coef (float) – weight for value loss, defaults to 0.5.
ent_coef (float) – weight for entropy loss, defaults to 0.01.
action_range ((float, float)) – the action range (minimum, maximum).
gae_lambda (float) – in [0, 1], param for Generalized Advantage Estimation, defaults to 0.95.
dual_clip (float) – a parameter c mentioned in arXiv:1912.09729 Equ. 5, where c > 1 is a constant indicating the lower bound, defaults to 5.0 (set
Noneif you do not want to use it).value_clip (bool) – a parameter mentioned in arXiv:1811.02553 Sec. 4.1, defaults to
True.reward_normalization (bool) – normalize the returns to Normal(0, 1), defaults to
True.
See also
Please refer to
BasePolicyfor more detailed explanation.-
forward(batch: tianshou.data.batch.Batch, state: Optional[Union[dict, tianshou.data.batch.Batch, numpy.ndarray]] = None, **kwargs) → tianshou.data.batch.Batch[source]¶ Compute action over the given batch data.
- Returns
A
Batchwhich has 4 keys:actthe action.logitsthe network’s raw output.distthe action distribution.statethe hidden state.
See also
Please refer to
forward()for more detailed explanation.
-
class
tianshou.policy.SACPolicy(actor: torch.nn.modules.module.Module, actor_optim: torch.optim.optimizer.Optimizer, critic1: torch.nn.modules.module.Module, critic1_optim: torch.optim.optimizer.Optimizer, critic2: torch.nn.modules.module.Module, critic2_optim: torch.optim.optimizer.Optimizer, tau: float = 0.005, gamma: float = 0.99, alpha: Tuple[float, torch.Tensor, torch.optim.optimizer.Optimizer] = 0.2, action_range: Optional[Tuple[float, float]] = None, reward_normalization: bool = False, ignore_done: bool = False, estimation_step: int = 1, exploration_noise: Optional[tianshou.exploration.random.BaseNoise] = None, **kwargs)[source]¶ Bases:
tianshou.policy.modelfree.ddpg.DDPGPolicyImplementation of Soft Actor-Critic. arXiv:1812.05905
- Parameters
actor (torch.nn.Module) – the actor network following the rules in
BasePolicy. (s -> logits)actor_optim (torch.optim.Optimizer) – the optimizer for actor network.
critic1 (torch.nn.Module) – the first critic network. (s, a -> Q(s, a))
critic1_optim (torch.optim.Optimizer) – the optimizer for the first critic network.
critic2 (torch.nn.Module) – the second critic network. (s, a -> Q(s, a))
critic2_optim (torch.optim.Optimizer) – the optimizer for the second critic network.
tau (float) – param for soft update of the target network, defaults to 0.005.
gamma (float) – discount factor, in [0, 1], defaults to 0.99.
exploration_noise (BaseNoise) – the noise intensity, add to the action, defaults to 0.1.
torch.Tensor, torch.optim.Optimizer) or float alpha ((float,) – entropy regularization coefficient, default to 0.2. If a tuple (target_entropy, log_alpha, alpha_optim) is provided, then alpha is automatatically tuned.
action_range ((float, float)) – the action range (minimum, maximum).
reward_normalization (bool) – normalize the reward to Normal(0, 1), defaults to
False.ignore_done (bool) – ignore the done flag while training the policy, defaults to
False.exploration_noise – add a noise to action for exploration. This is useful when solving hard-exploration problem.
See also
Please refer to
BasePolicyfor more detailed explanation.-
forward(batch: tianshou.data.batch.Batch, state: Optional[Union[dict, tianshou.data.batch.Batch, numpy.ndarray]] = None, input: str = 'obs', explorating: bool = True, **kwargs) → tianshou.data.batch.Batch[source]¶ Compute action over the given batch data.
- Returns
A
Batchwhich has 2 keys:actthe action.statethe hidden state.
See also
Please refer to
forward()for more detailed explanation.
-
class
tianshou.policy.TD3Policy(actor: torch.nn.modules.module.Module, actor_optim: torch.optim.optimizer.Optimizer, critic1: torch.nn.modules.module.Module, critic1_optim: torch.optim.optimizer.Optimizer, critic2: torch.nn.modules.module.Module, critic2_optim: torch.optim.optimizer.Optimizer, tau: float = 0.005, gamma: float = 0.99, exploration_noise: Optional[tianshou.exploration.random.BaseNoise] = <tianshou.exploration.random.GaussianNoise object>, policy_noise: float = 0.2, update_actor_freq: int = 2, noise_clip: float = 0.5, action_range: Optional[Tuple[float, float]] = None, reward_normalization: bool = False, ignore_done: bool = False, estimation_step: int = 1, **kwargs)[source]¶ Bases:
tianshou.policy.modelfree.ddpg.DDPGPolicyImplementation of Twin Delayed Deep Deterministic Policy Gradient, arXiv:1802.09477
- Parameters
actor (torch.nn.Module) – the actor network following the rules in
BasePolicy. (s -> logits)actor_optim (torch.optim.Optimizer) – the optimizer for actor network.
critic1 (torch.nn.Module) – the first critic network. (s, a -> Q(s, a))
critic1_optim (torch.optim.Optimizer) – the optimizer for the first critic network.
critic2 (torch.nn.Module) – the second critic network. (s, a -> Q(s, a))
critic2_optim (torch.optim.Optimizer) – the optimizer for the second critic network.
tau (float) – param for soft update of the target network, defaults to 0.005.
gamma (float) – discount factor, in [0, 1], defaults to 0.99.
exploration_noise (float) – the exploration noise, add to the action, defaults to
GaussianNoise(sigma=0.1)policy_noise (float) – the noise used in updating policy network, default to 0.2.
update_actor_freq (int) – the update frequency of actor network, default to 2.
noise_clip (float) – the clipping range used in updating policy network, default to 0.5.
action_range ((float, float)) – the action range (minimum, maximum).
reward_normalization (bool) – normalize the reward to Normal(0, 1), defaults to
False.ignore_done (bool) – ignore the done flag while training the policy, defaults to
False.
See also
Please refer to
BasePolicyfor more detailed explanation.