tianshou.data¶
-
class
tianshou.data.Batch(batch_dict: Optional[Union[dict, Batch, Tuple[Union[dict, Batch]], List[Union[dict, Batch]], numpy.ndarray]] = None, copy: bool = False, **kwargs)[source]¶ Bases:
objectTianshou provides
Batchas the internal data structure to pass any kind of data to other methods, for example, a collector gives aBatchto policy for learning. Here is the usage:>>> import numpy as np >>> from tianshou.data import Batch >>> data = Batch(a=4, b=[5, 5], c='2312312') >>> # the list will automatically be converted to numpy array >>> data.b array([5, 5]) >>> data.b = np.array([3, 4, 5]) >>> print(data) Batch( a: 4, b: array([3, 4, 5]), c: '2312312', )
In short, you can define a
Batchwith any key-value pair.For Numpy arrays, only data types with
np.object, bool, and number are supported. For strings or other data types, however, they can be held innp.objectarrays.The current implementation of Tianshou typically use 7 reserved keys in
Batch:obsthe observation of step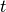 ;
;actthe action of step ;rewthe reward of step ;donethe done flag of step ;obs_nextthe observation of step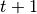 ;
;infothe info of step (in gym.Env, theenv.step()function returns 4 arguments, and the last one isinfo);policythe data computed by policy in step;
Batchobject can be initialized by a wide variety of arguments, ranging from the key/value pairs or dictionary, to list and Numpy arrays ofdictor Batch instances where each element is considered as an individual sample and get stacked together:>>> data = Batch([{'a': {'b': [0.0, "info"]}}]) >>> print(data[0]) Batch( a: Batch( b: array([0.0, 'info'], dtype=object), ), )
Batchhas the same API as a native Pythondict. In this regard, one can access stored data using string key, or iterate over stored data:>>> data = Batch(a=4, b=[5, 5]) >>> print(data["a"]) 4 >>> for key, value in data.items(): >>> print(f"{key}: {value}") a: 4 b: [5, 5]
Batchalso partially reproduces the Numpy API for arrays. It also supports the advanced slicing method, such as batch[:, i], if the index is valid. You can access or iterate over the individual samples, if any:>>> data = Batch(a=np.array([[0.0, 2.0], [1.0, 3.0]]), b=[[5, -5]]) >>> print(data[0]) Batch( a: array([0., 2.]) b: array([ 5, -5]), ) >>> for sample in data: >>> print(sample.a) [0., 2.] >>> print(data.shape) [1, 2] >>> data[:, 1] += 1 >>> print(data) Batch( a: array([[0., 3.], [1., 4.]]), b: array([[ 5, -4]]), )
Similarly, one can also perform simple algebra on it, and stack, split or concatenate multiple instances:
>>> data_1 = Batch(a=np.array([0.0, 2.0]), b=5) >>> data_2 = Batch(a=np.array([1.0, 3.0]), b=-5) >>> data = Batch.stack((data_1, data_2)) >>> print(data) Batch( b: array([ 5, -5]), a: array([[0., 2.], [1., 3.]]), ) >>> print(np.mean(data)) Batch( b: 0.0, a: array([0.5, 2.5]), ) >>> data_split = list(data.split(1, False)) >>> print(list(data.split(1, False))) [Batch( b: array([5]), a: array([[0., 2.]]), ), Batch( b: array([-5]), a: array([[1., 3.]]), )] >>> data_cat = Batch.cat(data_split) >>> print(data_cat) Batch( b: array([ 5, -5]), a: array([[0., 2.], [1., 3.]]), )
Note that stacking of inconsistent data is also supported. In which case,
Noneis added in list ornp.ndarrayof objects, 0 otherwise.>>> data_1 = Batch(a=np.array([0.0, 2.0])) >>> data_2 = Batch(a=np.array([1.0, 3.0]), b='done') >>> data = Batch.stack((data_1, data_2)) >>> print(data) Batch( a: array([[0., 2.], [1., 3.]]), b: array([None, 'done'], dtype=object), )
Method
empty_sets elements to 0 orNonefornp.object.>>> data.empty_() >>> print(data) Batch( a: array([[0., 0.], [0., 0.]]), b: array([None, None], dtype=object), ) >>> data = Batch(a=[False, True], b={'c': [2., 'st'], 'd': [1., 0.]}) >>> data[0] = Batch.empty(data[1]) >>> data Batch( a: array([False, True]), b: Batch( c: array([None, 'st']), d: array([0., 0.]), ), )
shape()and__len__()methods are also provided to respectively get the shape and the length of aBatchinstance. It mimics the Numpy API for Numpy arrays, which means that getting the length of a scalar Batch raises an exception.>>> data = Batch(a=[5., 4.], b=np.zeros((2, 3, 4))) >>> data.shape [2] >>> len(data) 2 >>> data[0].shape [] >>> len(data[0]) TypeError: Object of type 'Batch' has no len()
Convenience helpers are available to convert in-place the stored data into Numpy arrays or Torch tensors.
Finally, note that
Batchis serializable and therefore Pickle compatible. This is especially important for distributed sampling.-
__getitem__(index: Union[str, slice, int, numpy.integer, numpy.ndarray, List[int]]) → tianshou.data.batch.Batch[source]¶ Return self[index].
-
static
cat(batches: List[Union[dict, Batch]]) → tianshou.data.batch.Batch[source]¶ Concatenate a list of
Batchobject into a single new batch. For keys that are not shared across all batches, batches that do not have these keys will be padded by zeros with appropriate shapes. E.g.>>> a = Batch(a=np.zeros([3, 4]), common=Batch(c=np.zeros([3, 5]))) >>> b = Batch(b=np.zeros([4, 3]), common=Batch(c=np.zeros([4, 5]))) >>> c = Batch.cat([a, b]) >>> c.a.shape (7, 4) >>> c.b.shape (7, 3) >>> c.common.c.shape (7, 5)
-
cat_(batches: Union[Batch, List[Union[dict, Batch]]]) → None[source]¶ Concatenate a list of (or one)
Batchobjects into current batch.
-
static
empty(batch: tianshou.data.batch.Batch, index: Union[str, slice, int, numpy.integer, numpy.ndarray, List[int]] = None) → tianshou.data.batch.Batch[source]¶ Return an empty
Batchobject with 0 orNonefilled, the shape is the same as the givenBatch.
-
empty_(index: Union[str, slice, int, numpy.integer, numpy.ndarray, List[int]] = None) → tianshou.data.batch.Batch[source]¶ Return an empty a
Batchobject with 0 orNonefilled. Ifindexis specified, it will only reset the specific indexed-data.
-
get(k: str, d: Optional[Any] = None) → Union[tianshou.data.batch.Batch, Any][source]¶ Return self[k] if k in self else d. d defaults to None.
-
property
shape¶ Return self.shape.
-
split(size: Optional[int] = None, shuffle: bool = True) → Iterator[tianshou.data.batch.Batch][source]¶ Split whole data into multiple small batches.
- Parameters
size (int) – if it is
None, it does not split the data batch; otherwise it will divide the data batch with the given size. Default toNone.shuffle (bool) – randomly shuffle the entire data batch if it is
True, otherwise remain in the same. Default toTrue.
-
static
stack(batches: List[Union[dict, Batch]], axis: int = 0) → tianshou.data.batch.Batch[source]¶ Stack a list of
Batchobject into a single new batch. For keys that are not shared across all batches, batches that do not have these keys will be padded by zeros. E.g.>>> a = Batch(a=np.zeros([4, 4]), common=Batch(c=np.zeros([4, 5]))) >>> b = Batch(b=np.zeros([4, 6]), common=Batch(c=np.zeros([4, 5]))) >>> c = Batch.stack([a, b]) >>> c.a.shape (2, 4, 4) >>> c.b.shape (2, 4, 6) >>> c.common.c.shape (2, 4, 5)
Note
If there are keys that are not shared across all batches,
stackwithaxis != 0is undefined, and will cause an exception.
-
stack_(batches: List[Union[dict, Batch]], axis: int = 0) → None[source]¶ Stack a list of
Batchobject into current batch.
-
to_torch(dtype: Optional[torch.dtype] = None, device: Union[str, int, torch.device] = 'cpu') → None[source]¶ Change all numpy.ndarray to torch.Tensor. This is an in-place operation.
-
class
tianshou.data.Collector(policy: tianshou.policy.base.BasePolicy, env: Union[gym.core.Env, tianshou.env.vecenv.BaseVectorEnv], buffer: Optional[tianshou.data.buffer.ReplayBuffer] = None, preprocess_fn: Callable[[Any], Union[dict, tianshou.data.batch.Batch]] = None, stat_size: Optional[int] = 100, action_noise: Optional[tianshou.exploration.random.BaseNoise] = None, reward_metric: Optional[Callable[[numpy.ndarray], float]] = None, **kwargs)[source]¶ Bases:
objectThe
Collectorenables the policy to interact with different types of environments conveniently.- Parameters
policy – an instance of the
BasePolicyclass.env – a
gym.Envenvironment or an instance of theBaseVectorEnvclass.buffer – an instance of the
ReplayBufferclass, or a list ofReplayBuffer. If set toNone, it will automatically assign a small-sizeReplayBuffer.preprocess_fn (function) – a function called before the data has been added to the buffer, see issue #42 and Handle Batched Data Stream in Collector, defaults to
None.stat_size (int) – for the moving average of recording speed, defaults to 100.
action_noise (BaseNoise) – add a noise to continuous action. Normally a policy already has a noise param for exploration in training phase, so this is recommended to use in test collector for some purpose.
reward_metric (function) – to be used in multi-agent RL. The reward to report is of shape [agent_num], but we need to return a single scalar to monitor training. This function specifies what is the desired metric, e.g., the reward of agent 1 or the average reward over all agents. By default, the behavior is to select the reward of agent 1.
The
preprocess_fnis a function called before the data has been added to the buffer with batch format, which receives up to 7 keys as listed inBatch. It will receive with onlyobswhen the collector resets the environment. It returns either a dict or aBatchwith the modified keys and values. Examples are in “test/base/test_collector.py”.Example:
policy = PGPolicy(...) # or other policies if you wish env = gym.make('CartPole-v0') replay_buffer = ReplayBuffer(size=10000) # here we set up a collector with a single environment collector = Collector(policy, env, buffer=replay_buffer) # the collector supports vectorized environments as well envs = VectorEnv([lambda: gym.make('CartPole-v0') for _ in range(3)]) buffers = [ReplayBuffer(size=5000) for _ in range(3)] # you can also pass a list of replay buffer to collector, for multi-env # collector = Collector(policy, envs, buffer=buffers) collector = Collector(policy, envs, buffer=replay_buffer) # collect at least 3 episodes collector.collect(n_episode=3) # collect 1 episode for the first env, 3 for the third env collector.collect(n_episode=[1, 0, 3]) # collect at least 2 steps collector.collect(n_step=2) # collect episodes with visual rendering (the render argument is the # sleep time between rendering consecutive frames) collector.collect(n_episode=1, render=0.03) # sample data with a given number of batch-size: batch_data = collector.sample(batch_size=64) # policy.learn(batch_data) # btw, vanilla policy gradient only # supports on-policy training, so here we pick all data in the buffer batch_data = collector.sample(batch_size=0) policy.learn(batch_data) # on-policy algorithms use the collected data only once, so here we # clear the buffer collector.reset_buffer()
For the scenario of collecting data from multiple environments to a single buffer, the cache buffers will turn on automatically. It may return the data more than the given limitation.
Note
Please make sure the given environment has a time limitation.
-
collect(n_step: int = 0, n_episode: Union[int, List[int]] = 0, random: bool = False, render: Optional[float] = None, log_fn: Optional[Callable[[dict], None]] = None) → Dict[str, float][source]¶ Collect a specified number of step or episode.
- Parameters
n_step (int) – how many steps you want to collect.
n_episode (int or list) – how many episodes you want to collect (in each environment).
random (bool) – whether to use random policy for collecting data, defaults to
False.render (float) – the sleep time between rendering consecutive frames, defaults to
None(no rendering).log_fn (function) – a function which receives env info, typically for tensorboard logging.
Note
One and only one collection number specification is permitted, either
n_steporn_episode.- Returns
A dict including the following keys
n/epthe collected number of episodes.n/stthe collected number of steps.v/stthe speed of steps per second.v/epthe speed of episode per second.rewthe mean reward over collected episodes.lenthe mean length over collected episodes.
-
reset_env() → None[source]¶ Reset all of the environment(s)’ states and reset all of the cache buffers (if need).
-
sample(batch_size: int) → tianshou.data.batch.Batch[source]¶ Sample a data batch from the internal replay buffer. It will call
process_fn()before returning the final batch data.- Parameters
batch_size (int) –
0means it will extract all the data from the buffer, otherwise it will extract the data with the given batch_size.
-
class
tianshou.data.ListReplayBuffer(**kwargs)[source]¶ Bases:
tianshou.data.buffer.ReplayBufferThe function of
ListReplayBufferis almost the same asReplayBuffer. The only difference is thatListReplayBufferis based onlist. Therefore, it does not support advanced indexing, which means you cannot sample a batch of data out of it. It is typically used for storing data.See also
Please refer to
ReplayBufferfor more detailed explanation.
-
class
tianshou.data.PrioritizedReplayBuffer(size: int, alpha: float, beta: float, mode: str = 'weight', replace: bool = False, **kwargs)[source]¶ Bases:
tianshou.data.buffer.ReplayBufferPrioritized replay buffer implementation.
- Parameters
alpha (float) – the prioritization exponent.
beta (float) – the importance sample soft coefficient.
mode (str) – defaults to
weight.replace (bool) – whether to sample with replacement
See also
Please refer to
ReplayBufferfor more detailed explanation.-
__getitem__(index: Union[slice, int, numpy.integer, numpy.ndarray]) → tianshou.data.batch.Batch[source]¶ Return a data batch: self[index]. If stack_num is set to be > 0, return the stacked obs and obs_next with shape [batch, len, …].
-
add(obs: Union[dict, numpy.ndarray], act: Union[numpy.ndarray, float], rew: Union[int, float], done: bool, obs_next: Optional[Union[dict, numpy.ndarray]] = None, info: dict = {}, policy: Optional[Union[dict, tianshou.data.batch.Batch]] = {}, weight: float = 1.0, **kwargs) → None[source]¶ Add a batch of data into replay buffer.
-
property
replace¶
-
class
tianshou.data.ReplayBuffer(size: int, stack_num: Optional[int] = 0, ignore_obs_next: bool = False, sample_avail: bool = False, **kwargs)[source]¶ Bases:
objectReplayBufferstores data generated from interaction between the policy and environment. It stores basically 7 types of data, as mentioned inBatch, based onnumpy.ndarray. Here is the usage:>>> import numpy as np >>> from tianshou.data import ReplayBuffer >>> buf = ReplayBuffer(size=20) >>> for i in range(3): ... buf.add(obs=i, act=i, rew=i, done=i, obs_next=i + 1, info={}) >>> len(buf) 3 >>> buf.obs # since we set size = 20, len(buf.obs) == 20. array([0., 1., 2., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]) >>> buf2 = ReplayBuffer(size=10) >>> for i in range(15): ... buf2.add(obs=i, act=i, rew=i, done=i, obs_next=i + 1, info={}) >>> len(buf2) 10 >>> buf2.obs # since its size = 10, it only stores the last 10 steps' result. array([10., 11., 12., 13., 14., 5., 6., 7., 8., 9.]) >>> # move buf2's result into buf (meanwhile keep it chronologically) >>> buf.update(buf2) array([ 0., 1., 2., 5., 6., 7., 8., 9., 10., 11., 12., 13., 14., 0., 0., 0., 0., 0., 0., 0.]) >>> # get a random sample from buffer >>> # the batch_data is equal to buf[incide]. >>> batch_data, indice = buf.sample(batch_size=4) >>> batch_data.obs == buf[indice].obs array([ True, True, True, True])
ReplayBufferalso supports frame_stack sampling (typically for RNN usage, see issue#19), ignoring storing the next observation (save memory in atari tasks), and multi-modal observation (see issue#38):>>> buf = ReplayBuffer(size=9, stack_num=4, ignore_obs_next=True) >>> for i in range(16): ... done = i % 5 == 0 ... buf.add(obs={'id': i}, act=i, rew=i, done=done, ... obs_next={'id': i + 1}) >>> print(buf) # you can see obs_next is not saved in buf ReplayBuffer( act: array([ 9., 10., 11., 12., 13., 14., 15., 7., 8.]), done: array([0., 1., 0., 0., 0., 0., 1., 0., 0.]), info: Batch(), obs: Batch( id: array([ 9., 10., 11., 12., 13., 14., 15., 7., 8.]), ), policy: Batch(), rew: array([ 9., 10., 11., 12., 13., 14., 15., 7., 8.]), ) >>> index = np.arange(len(buf)) >>> print(buf.get(index, 'obs').id) [[ 7. 7. 8. 9.] [ 7. 8. 9. 10.] [11. 11. 11. 11.] [11. 11. 11. 12.] [11. 11. 12. 13.] [11. 12. 13. 14.] [12. 13. 14. 15.] [ 7. 7. 7. 7.] [ 7. 7. 7. 8.]] >>> # here is another way to get the stacked data >>> # (stack only for obs and obs_next) >>> abs(buf.get(index, 'obs')['id'] - buf[index].obs.id).sum().sum() 0.0 >>> # we can get obs_next through __getitem__, even if it doesn't exist >>> print(buf[:].obs_next.id) [[ 7. 8. 9. 10.] [ 7. 8. 9. 10.] [11. 11. 11. 12.] [11. 11. 12. 13.] [11. 12. 13. 14.] [12. 13. 14. 15.] [12. 13. 14. 15.] [ 7. 7. 7. 8.] [ 7. 7. 8. 9.]]
- Parameters
size (int) – the size of replay buffer.
stack_num (int) – the frame-stack sampling argument, should be greater than 1, defaults to 0 (no stacking).
ignore_obs_next (bool) – whether to store obs_next, defaults to
False.sample_avail (bool) – the parameter indicating sampling only available index when using frame-stack sampling method, defaults to
False. This feature is not supported in Prioritized Replay Buffer currently.
-
__getitem__(index: Union[slice, int, numpy.integer, numpy.ndarray]) → tianshou.data.batch.Batch[source]¶ Return a data batch: self[index]. If stack_num is set to be > 0, return the stacked obs and obs_next with shape [batch, len, …].
-
add(obs: Union[dict, tianshou.data.batch.Batch, numpy.ndarray], act: Union[numpy.ndarray, float], rew: Union[int, float], done: bool, obs_next: Optional[Union[dict, tianshou.data.batch.Batch, numpy.ndarray]] = None, info: dict = {}, policy: Optional[Union[dict, tianshou.data.batch.Batch]] = {}, **kwargs) → None[source]¶ Add a batch of data into replay buffer.
-
get(indice: Union[slice, int, numpy.integer, numpy.ndarray], key: str, stack_num: Optional[int] = None) → Union[tianshou.data.batch.Batch, numpy.ndarray][source]¶ Return the stacked result, e.g. [s_{t-3}, s_{t-2}, s_{t-1}, s_t], where s is self.key, t is indice. The stack_num (here equals to 4) is given from buffer initialization procedure.
-
tianshou.data.to_numpy(x: Union[torch.Tensor, dict, tianshou.data.batch.Batch, numpy.ndarray]) → Union[dict, tianshou.data.batch.Batch, numpy.ndarray][source]¶ Return an object without torch.Tensor.