tianshou.data¶
-
class
tianshou.data.Batch(**kwargs)[source]¶ Bases:
objectTianshou provides
Batchas the internal data structure to pass any kind of data to other methods, for example, a collector gives aBatchto policy for learning. Here is the usage:>>> import numpy as np >>> from tianshou.data import Batch >>> data = Batch(a=4, b=[5, 5], c='2312312') >>> data.b [5, 5] >>> data.b = np.array([3, 4, 5]) >>> len(data.b) 3 >>> data.b[-1] 5
In short, you can define a
Batchwith any key-value pair. The current implementation of Tianshou typically use 6 keys inBatch:obsthe observation of step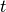 ;
;actthe action of step ;rewthe reward of step ;donethe done flag of step ;obs_nextthe observation of step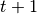 ;
;infothe info of step (in gym.Env, theenv.step()function return 4 arguments, and the last one isinfo);
Batchhas other methods, including__getitem__(),__len__(),append(), andsplit():>>> data = Batch(obs=np.array([0, 11, 22]), rew=np.array([6, 6, 6])) >>> # here we test __getitem__ >>> index = [2, 1] >>> data[index].obs array([22, 11]) >>> # here we test __len__ >>> len(data) 3 >>> data.append(data) # similar to list.append >>> data.obs array([0, 11, 22, 0, 11, 22]) >>> # split whole data into multiple small batch >>> for d in data.split(size=2, permute=False): ... print(d.obs, d.rew) [ 0 11] [6 6] [22 0] [6 6] [11 22] [6 6]
-
split(size=None, permute=True)[source]¶ Split whole data into multiple small batch.
- Parameters
size (int) – if it is
None, it does not split the data batch; otherwise it will divide the data batch with the given size. Default toNone.permute (bool) – randomly shuffle the entire data batch if it is
True, otherwise remain in the same. Default toTrue.
-
class
tianshou.data.ReplayBuffer(size)[source]¶ Bases:
objectReplayBufferstores data generated from interaction between the policy and environment. It stores basically 6 types of data, as mentioned inBatch, based onnumpy.ndarray. Here is the usage:>>> from tianshou.data import ReplayBuffer >>> buf = ReplayBuffer(size=20) >>> for i in range(3): ... buf.add(obs=i, act=i, rew=i, done=i, obs_next=i + 1, info={}) >>> len(buf) 3 >>> buf.obs # since we set size = 20, len(buf.obs) == 20. array([0., 1., 2., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]) >>> buf2 = ReplayBuffer(size=10) >>> for i in range(15): ... buf2.add(obs=i, act=i, rew=i, done=i, obs_next=i + 1, info={}) >>> len(buf2) 10 >>> buf2.obs # since its size = 10, it only stores the last 10 steps' result. array([10., 11., 12., 13., 14., 5., 6., 7., 8., 9.]) >>> # move buf2's result into buf (meanwhile keep it chronologically) >>> buf.update(buf2) array([ 0., 1., 2., 5., 6., 7., 8., 9., 10., 11., 12., 13., 14., 0., 0., 0., 0., 0., 0., 0.]) >>> # get a random sample from buffer >>> # the batch_data is equal to buf[incide]. >>> batch_data, indice = buf.sample(batch_size=4) >>> batch_data.obs == buf[indice].obs array([ True, True, True, True])
-
add(obs, act, rew, done, obs_next=0, info={}, weight=None)[source]¶ Add a batch of data into replay buffer.
-
-
class
tianshou.data.ListReplayBuffer[source]¶ Bases:
tianshou.data.buffer.ReplayBufferThe function of
ListReplayBufferis almost the same asReplayBuffer. The only difference is thatListReplayBufferis based onlist.
-
class
tianshou.data.PrioritizedReplayBuffer(size)[source]¶ Bases:
tianshou.data.buffer.ReplayBufferdocstring for PrioritizedReplayBuffer
-
class
tianshou.data.Collector(policy, env, buffer=None, stat_size=100, store_obs_next=True, **kwargs)[source]¶ Bases:
objectThe
Collectorenables the policy to interact with different types of environments conveniently.- Parameters
policy – an instance of the
BasePolicyclass.env – an environment or an instance of the
BaseVectorEnvclass.buffer – an instance of the
ReplayBufferclass, or a list ofReplayBuffer. If set toNone, it will automatically assign a small-sizeReplayBuffer.stat_size (int) – for the moving average of recording speed, defaults to 100.
store_obs_next (bool) – whether to store the obs_next to replay buffer, defaults to
True.
Example:
policy = PGPolicy(...) # or other policies if you wish env = gym.make('CartPole-v0') replay_buffer = ReplayBuffer(size=10000) # here we set up a collector with a single environment collector = Collector(policy, env, buffer=replay_buffer) # the collector supports vectorized environments as well envs = VectorEnv([lambda: gym.make('CartPole-v0') for _ in range(3)]) buffers = [ReplayBuffer(size=5000) for _ in range(3)] # you can also pass a list of replay buffer to collector, for multi-env # collector = Collector(policy, envs, buffer=buffers) collector = Collector(policy, envs, buffer=replay_buffer) # collect at least 3 episodes collector.collect(n_episode=3) # collect 1 episode for the first env, 3 for the third env collector.collect(n_episode=[1, 0, 3]) # collect at least 2 steps collector.collect(n_step=2) # collect episodes with visual rendering (the render argument is the # sleep time between rendering consecutive frames) collector.collect(n_episode=1, render=0.03) # sample data with a given number of batch-size: batch_data = collector.sample(batch_size=64) # policy.learn(batch_data) # btw, vanilla policy gradient only # supports on-policy training, so here we pick all data in the buffer batch_data = collector.sample(batch_size=0) policy.learn(batch_data) # on-policy algorithms use the collected data only once, so here we # clear the buffer collector.reset_buffer()
For the scenario of collecting data from multiple environments to a single buffer, the cache buffers will turn on automatically. It may return the data more than the given limitation.
Note
Please make sure the given environment has a time limitation.
-
collect(n_step=0, n_episode=0, render=0)[source]¶ Collect a specified number of step or episode.
- Parameters
n_step (int) – how many steps you want to collect.
n_episode (int or list) – how many episodes you want to collect (in each environment).
render (float) – the sleep time between rendering consecutive frames. No rendering if it is
0(default option).
Note
One and only one collection number specification is permitted, either
n_steporn_episode.- Returns
A dict including the following keys
n/epthe collected number of episodes.n/stthe collected number of steps.v/stthe speed of steps per second.v/epthe speed of episode per second.rewthe mean reward over collected episodes.lenthe mean length over collected episodes.
-
reset_env()[source]¶ Reset all of the environment(s)’ states and reset all of the cache buffers (if need).
-
sample(batch_size)[source]¶ Sample a data batch from the internal replay buffer. It will call
process_fn()before returning the final batch data.- Parameters
batch_size (int) –
0means it will extract all the data from the buffer, otherwise it will extract the data with the given batch_size.